 旺旺头条
旺旺头条研研说之融数贯统:统计学如何为富集设计精准导航(下篇)

“融数贯统”
“研研说”之“融数贯统”系列专栏,旨在聚焦临床试验中的数统领域,以专业视角解析数据管理策略、统计方法应用及编程实践,带您全方位领略数统科学的精妙所在。本期研研说,我们将以随机系统搭建和测试以及药物供应管理为侧重点,给大家分享一些重点信息和注意事项。
在临床试验的日常推进过程中,因研究方案的差异,我们会面临多样化的研究设计。多数方案中均涉及随机化、开放/单盲/双盲设计,以及单中心或多中心的试验架构。本期我们将聚焦实践,聊聊富集设计如何成为推动突破性疗法早日问世的重要“加速器”。
随机系统搭建流程与注意事项
试验简介:
研究疾病:HER阳性/低表达乳腺癌;
总体人群: HER阳性/低表达乳腺癌;富集人群:HER2阳性乳腺癌人群;入组比例约为60%;
治疗:HER2 ADC药物 vs 化疗
主要终点指标: PFS;
样本量计算:
入组比例:1:1,脱落率:15%,入组期:12个月,随访期:12个月
中位PFS:总体人群:10个月 vs 6个月;富集人群:12个月 vs 6个月
把握度:90%
事件数:总体人群:163个;富集人群:89个
样本量:总体人群244人,每组122人;富集人群:148人,每组74人
本研究首先在HER2阳性人群中进行假设检验,如果拒绝原假设,则把 α 传递给全人群,在全人群中做假设检验。
试验检验顺序以及α传递:
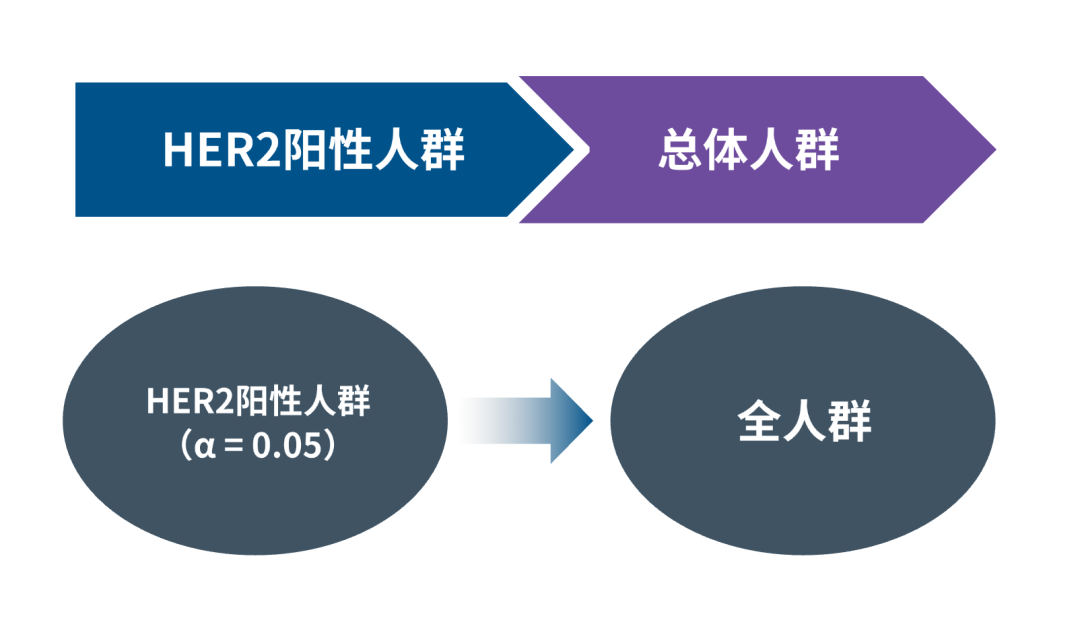
案例2:适应性富集设计

同章节“适应性富集设计的统计学考量” ,CP(F)为全人群的conditional power,CP(S)为特定亚组的conditional power。
适应性富集设计案例模拟情景:
案例1:控制整体人群效应值一致,标志物高表达和低表达效应值差距变大

案例2:控制标志物高表达和低表达效应值差距,整体人群效应值变大
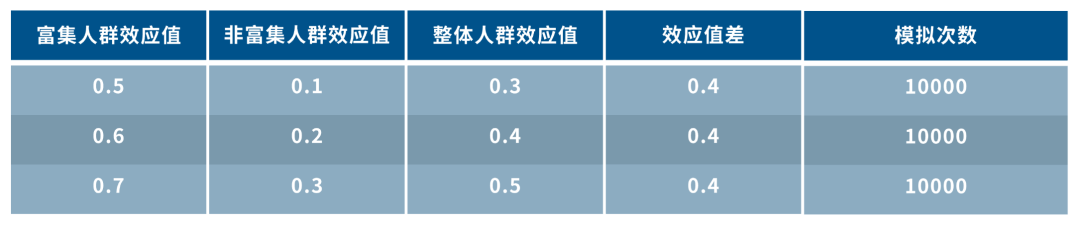
适应性富集设计案例模拟结果
案例1:控制整体人群效应值一致,控制整体人群效应值一致的情况下,标志物高表达受试者和低表达受试者差距越大,进入富集区域的概率越大,且富集区域例的试验成功率越高。
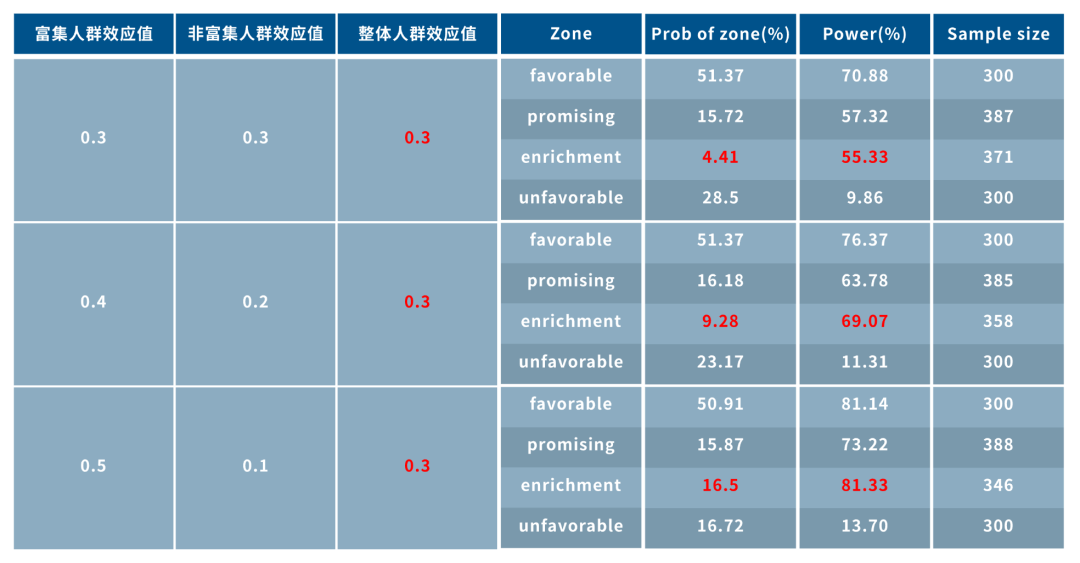
案例2:控制标志物高表达和低表达受试者效应值差距一致的情况下,整体效应值越高,进入有效区间概率越大且进入有效区间的试验成功率越高,提示标志物高表达受试者的效应值过高可能会拉高整体疗效,导致认为标志物低表达受试者也有效的情况。
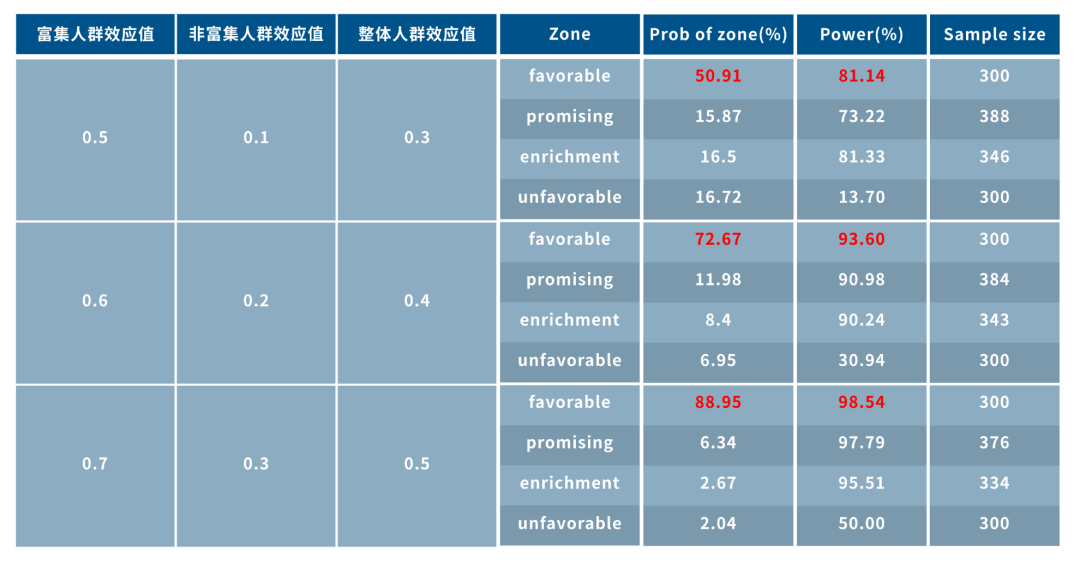
根据模拟结果,可以得出结论:若生物标志物阳性受试者和阴性受试者疗效有明显的差距,且差距并不小,使用适应性富集设计策略,可以提高进入富集区域的概率,从而提高试验成功率;但也应注意,若生物标志物阳性受试者疗效过高,且全人群中阳性受试者比例大,则可能拉高整体疗效,导致认为阴性受试者也会有疗效的结论,这不仅仅是适应性富集设计的风险,任何临床试验都会有这样的风险。

总结来说,富集设计绝非简单的统计学技巧,而是一场贯穿药物研发核心的战略革命。 它将我们的研发范式从“广撒网”的普适性探索,转变为“精聚焦”的精准化突破。我们也再次总结一些TIPS,将这种精准研发的理念带入实际工作中,共同推动更多创新药物的诞生。




版权声明
本文仅作者转发或者创作,不代表旺旺头条立场。
如有侵权请联系站长删除




发表评论:
◎欢迎参与讨论,请在这里发表您的看法、交流您的观点。