 旺旺头条
旺旺头条解锁自动驾驶新境界:VLA 模型的多维应用与突破

VLA 模型最早由 DeepMind 于 2023 年提出并应用在机器人领域,其诞生是为了打破传统人工智能模型在多模态交互与复杂任务执行上的局限。在当时,人工智能技术在单一模态处理上已取得显著成果,但在面对现实世界中多源异构信息融合与复杂决策任务时,表现却不尽人意。例如,传统自动驾驶系统往往将视觉感知与路径规划独立处理,缺乏对环境语义的深度理解和自然语言交互能力,难以应对复杂多变的交通场景。

随着人工智能从单一模态向多模态融合发展,以及自动驾驶对车辆理解复杂指令、灵活应对多变路况需求的提升,VLA 模型逐步被引入自动驾驶领域。自动驾驶技术的发展要求车辆不仅能够准确感知周围环境,还需要理解人类的自然语言指令,并据此做出合理的驾驶决策。VLA 模型整合了视觉、语言和动作三种能力,旨在实现从环境感知、语义理解到动作执行的完整闭环控制,为自动驾驶汽车赋予更接近人类驾驶员的决策与操作能力,成为推动自动驾驶技术向更高阶发展的关键技术之一。
1. 整体框架与核心组件
VLA 模型的整体框架可视为视觉语言模型(VLM)与端到端模型的结合体,这种独特的架构设计使其能够充分发挥不同模型的优势,实现高效的多模态信息处理与决策。其核心组件包括视觉编码器、文本编码器、轨迹解码器与文本解码器,各组件相互协作,共同完成从输入到输出的复杂任务。
如下图是谷歌RT-2的VLA模型。RT-2可以从网络和机器人的数据中学习,并将这些知识转化为机器人控制通用指令,帮助机器人在未曾见过的现实环境中完成各种复杂任务,同时提高机器人适应性和推理能力。其中,视觉编码器将图像进行patch切分后输入ViT进行编解码,最后生成Robotic需要执行的控制执行指令。
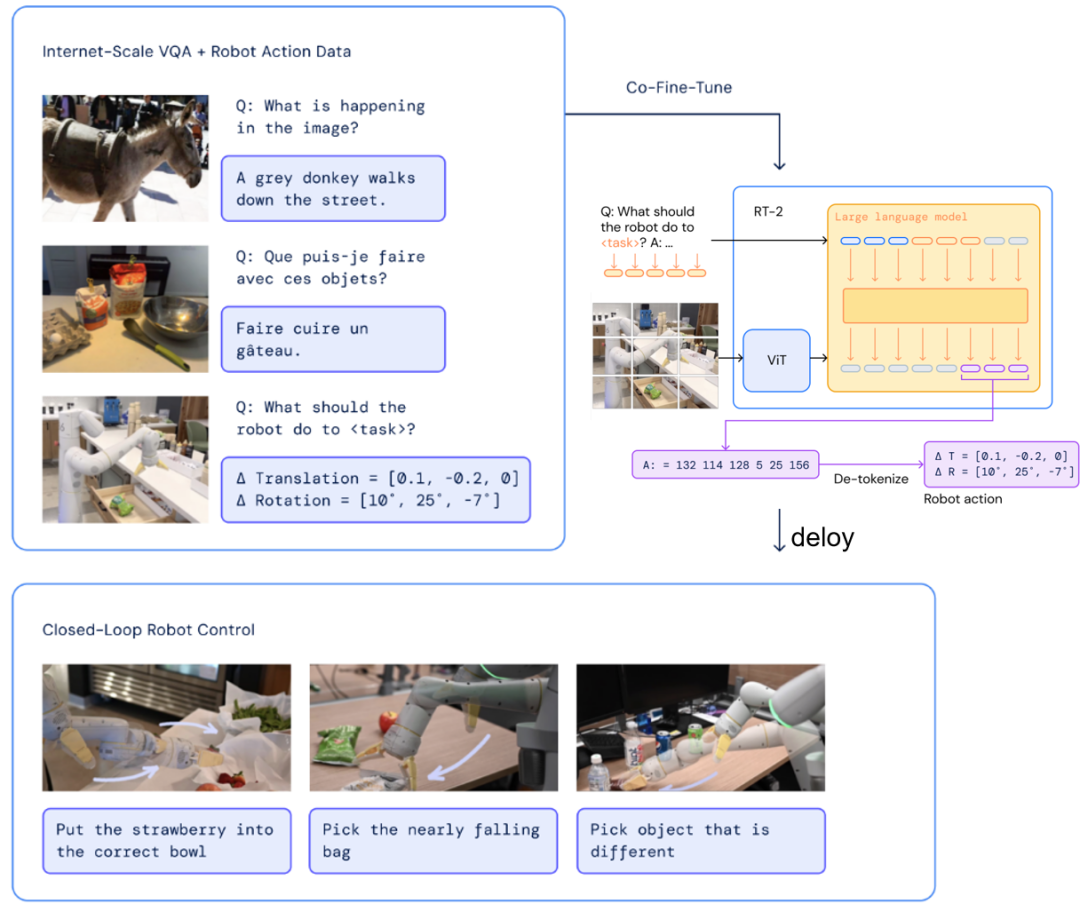
由于动作被表示为文本字符串,我们可以将其视为另一种能够操控机器人的"语言"。这种简洁的表示方法使得对现有“视觉—语言”模型进行微调,并将其转化为“视觉-语言-动作”模型变得直接而高效。
视觉编码器负责提取图像的高级特征,通常基于卷积神经网络(CNN)或 Transformer 架构。CNN 通过卷积层、池化层和全连接层逐步提取图像的局部特征,在图像识别领域取得了广泛应用。而近年来兴起的 ViT(Vision Transformer)模型则将图像分割成固定大小的 patches,通过自注意力机制对这些 patches 进行编码,能够更好地捕捉图像的全局语义信息。例如,在自动驾驶场景中,视觉编码器可以快速识别道路上的车辆、行人、交通标志等目标,并将其转化为模型可理解的特征向量,为后续决策提供基础。
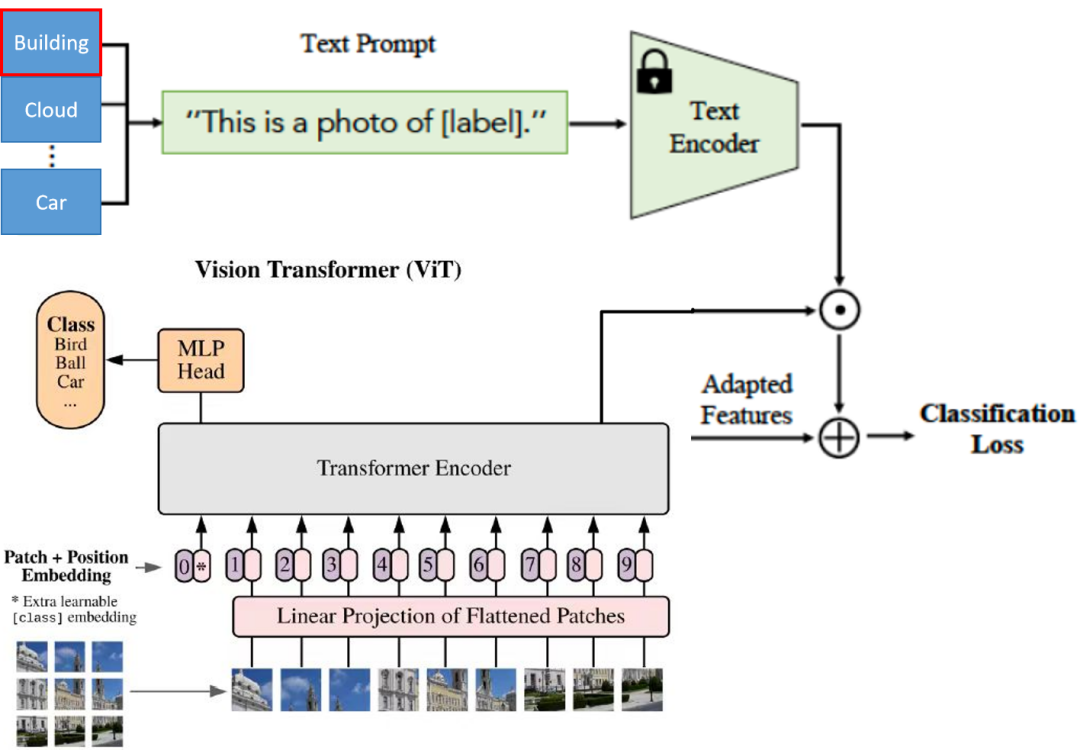
文本编码器利用自然语言处理技术,基于预训练语言模型(如 BERT、GPT 等)处理用户指令或导航信息。这些预训练模型在大规模文本数据上进行训练,学习到了丰富的语言知识和语义表示。当输入自然语言指令时,文本编码器首先通过词嵌入技术将每个单词转化为低维向量,然后利用注意力机制对句子中的不同单词进行加权处理,突出关键信息,最终将文本转换为模型可理解的内部表示。例如,当驾驶员发出 “前方路口左转,寻找停车场” 的指令时,文本编码器能够准确解析指令中的语义信息,并与视觉信息融合,为车辆的决策提供指导。
仍旧基于RT-2的例子进行说明。为使RT-2能够轻松兼容大规模预训练的视觉-语言模型,方案十分简洁:将机器人动作视为另一种语言,可转化为文本标记(text tokens),并与互联网规模的视觉-语言数据集共同训练。具体而言,采用协同微调(结合微调与协同训练的技术,保留部分原始视觉及文本数据)方法,在现有视觉-语言模型基础上融入机器人数据。这些数据包括当前图像、语言指令以及特定时间步的机器人动作。如下图所示,如果将机器人动作表示为文本字符串,例如由机器人动作标记编号组成的序列:

轨迹解码器根据视觉编码器和文本编码器的输出,采用序列生成模型(如循环神经网络 RNN 或 Transformer)生成未来 10 - 30 秒的驾驶路径。在生成路径时,轨迹解码器需要综合考虑车辆动力学特性、道路环境及交通规则等因素。例如,在遇到弯道时,轨迹解码器会根据车辆的转向性能和弯道半径,生成安全合理的转向轨迹;在交通拥堵时,会规划避免频繁加减速的行驶路径,以提升乘坐舒适性与通行效率。
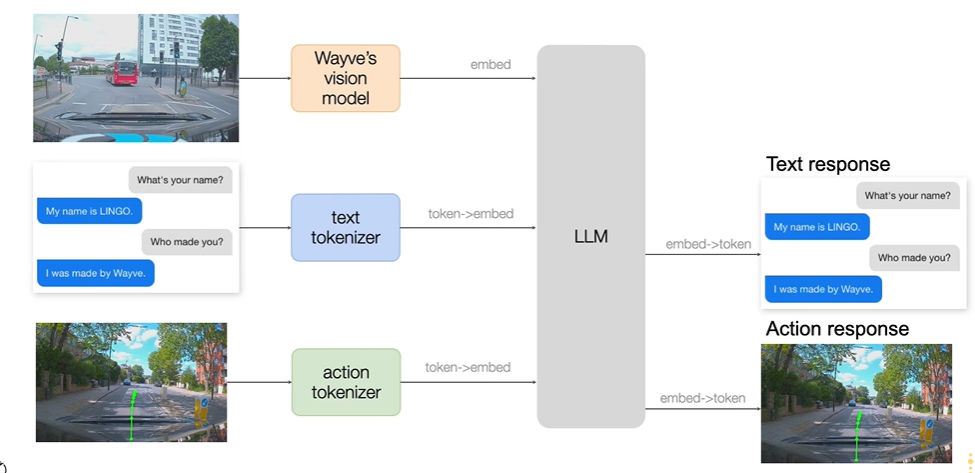
文本解码器基于预训练语言模型,经微调将模型决策过程以自然语言形式解释。在自动驾驶过程中,用户可能希望了解车辆做出决策的原因,文本解码器通过序列到序列学习,将模型内部的决策逻辑转化为人类可理解的解释文本。例如,当车辆选择绕行某路段时,文本解码器可以生成 “前方路段发生事故,为避免拥堵,选择绕行” 的解释,增强用户对自动驾驶系统的信任。
如下图表示了基于视频图像结合文本信息输入后生成了对应了决策指令。
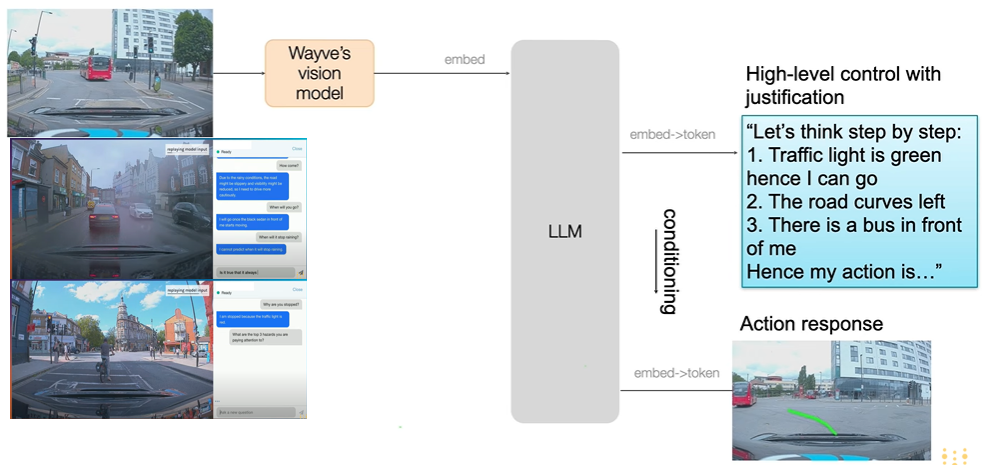
2. 多模态融合机制
多模态融合是 VLA 模型的关键优势,它使得模型能够充分利用不同模态的信息,提升对复杂场景的理解和应对能力。在 VLA 模型中,多模态融合主要发生在特征提取阶段和决策阶段。
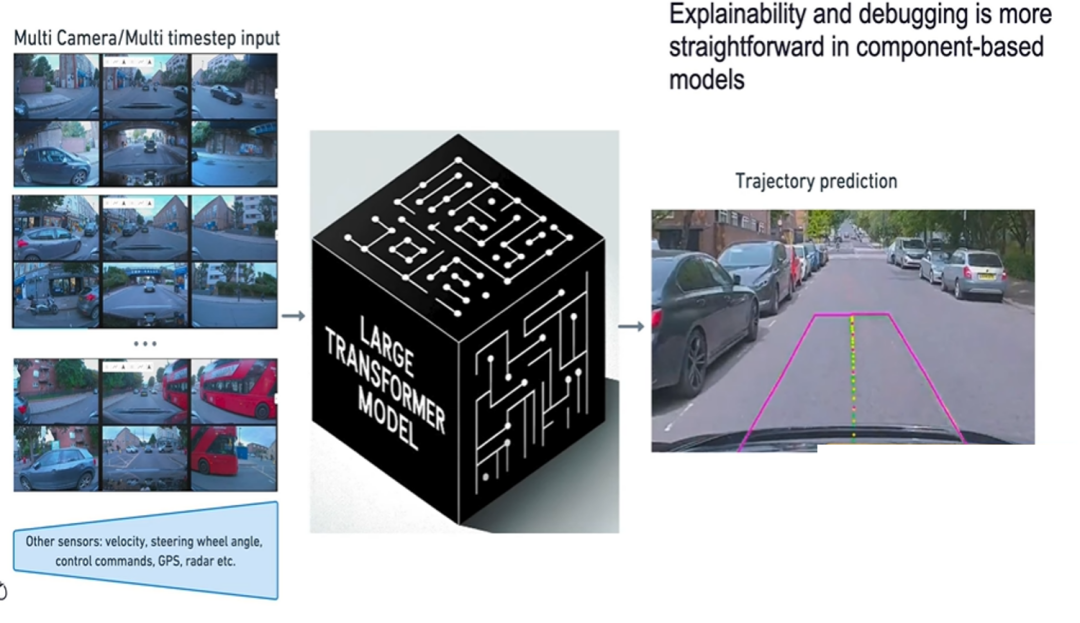
在特征提取阶段,通过特征级融合将不同视角图像特征拼接或加权融合。例如,在自动驾驶车辆上,通常配备多个摄像头,分别负责不同视角的图像采集。特征级融合可以将这些不同视角的图像特征进行整合,形成更全面的环境表示。具体来说,可以将来自前视、后视、侧视摄像头的特征向量进行拼接,或者根据不同摄像头的重要性进行加权求和,从而获取包含丰富空间信息的特征表示。
在决策阶段,决策级融合将各视角独立处理后的决策结果综合。当不同模态的信息经过各自的处理路径得到初步决策后,决策级融合会对这些决策进行整合,以得到最终的驾驶决策。例如,视觉信息显示前方道路畅通,而导航信息提示即将到达目的地需要减速,决策级融合会综合这两个信息,做出减速并准备停车的决策。
在实际应用中,交叉注意力机制是实现多模态融合的重要手段。以识别交通场景为例,视觉编码器提取的道路、车辆、行人等视觉特征,与文本编码器处理的交通标志文字、导航指令等语言特征,通过交叉注意力机制实现模态对齐。交叉注意力机制使得模型能够在不同模态之间建立联系,关注与当前任务相关的信息,从而使模型全面理解场景信息,生成精准动作指令。
同时,模型训练时利用大规模多模态数据,涵盖各种天气、光照、路况下的视觉数据,丰富多样的语言指令与对话,以及精确记录的车辆动作数据。为了进一步提升数据质量与数量,研究人员还会通过数据增强、合成等技术对数据进行处理。例如,通过对图像进行旋转、缩放、添加噪声等操作进行数据增强,模拟不同的拍摄角度和环境条件;利用合成技术生成虚拟的交通场景,增加训练数据的多样性,保障多模态融合效果。
3. VLA 模型的应用场景
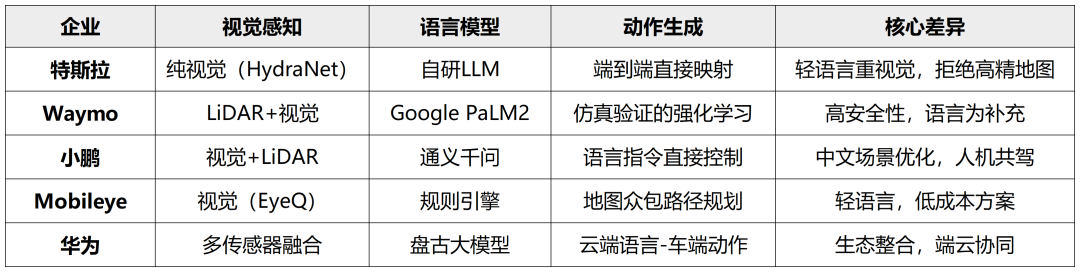
VLA技术正推动自动驾驶从“感知-规划”传统范式向“多模态交互-自主决策”演进。国际厂商注重技术极限突破,而国内企业更聚焦场景落地与用户体验。由于VLA模型的应用可以在很多无法为当前驾驶辅助场景所解决的corner case上发挥很好的效能。比如,语言模型深度整合中,LLM从交互层向决策层渗透(如华为、Waymo)。而视觉-动作端到端化中,特斯拉方案推动“输入-输出”直接学习,但泛化性存疑。本土化适配方面,中文复杂指令处理将成为国内厂商(小鹏、华为)差异化优势。未来,随着多模态大模型(如GPT-4V)的成熟,VLA或将成为L4+自动驾驶的标配技术架构。

3.1 日常驾驶场景
在日常城市道路驾驶中,VLA 模型已展现出强大的实用性。例如,理想汽车搭载 MindVLA 架构的测试车辆,在北京市区高峰时段的驾驶测试中,面对复杂多变的路况,能够精准识别交通信号灯、行人、其他车辆等元素。当遇到前方路口红灯时,模型结合视觉捕捉到的信号灯状态与地图数据,提前 100 米就开始规划减速停车策略,平稳地将车辆停在停止线前。在拥堵路段,它可理解周围车辆的行驶意图,当驾驶员发出 “寻找最近的出口” 指令后,通过语言模型解析指令,迅速规划合理的变道和驶出路线,避免频繁加减速,相比传统自动驾驶系统,通行效率提升约 20%。在高速公路场景下,特斯拉 FSD V12 系统能根据导航信息自动选择最优车道,保持安全车距,在一次从上海至杭州的测试中,车辆在遇到施工路段时,迅速分析路况并调整路线,全程无需人工干预,展现了在长距离驾驶中的稳定性。
3.2 复杂特殊场景
面对恶劣天气和复杂路况,VLA 模型的多传感器融合优势尤为突出。华为 ADS 3.0 系统在内蒙古冬季的极寒大雾天气测试中,激光雷达与摄像头等传感器协同工作,即使能见度不足 50 米,依然能准确感知道路边界、障碍物位置,车辆以安全速度平稳行驶,成功完成了 100 公里的测试路段。在复杂路况方面,小鹏汽车的 XNGP 系统在重庆的 “8D 魔幻” 道路测试中,凭借 VLA 模型强大的视觉理解与语言交互能力,在狭窄巷道和无标线道路中,依据驾驶员 “小心右侧电动车” 的语音提示,谨慎规划通过路径,顺利通过多个复杂路口。
3.3 交互与个性化场景
VLA 模型带来的智能交互与个性化体验也逐渐成为现实。在理想汽车的实际测试中,驾驶员说出 “我感觉有点累,开慢点”,车辆立即降低行驶速度,并调整驾驶风格,变得更加平稳柔和;当发出 “下一个路口右转,找一家咖啡店” 指令时,车辆不仅调整导航路线,还在到达附近区域后,通过与云端数据交互,筛选出评分较高的咖啡店,并规划前往路线。小鹏汽车通过分析用户历史驾驶数据,为不同驾驶风格偏好的用户提供个性化体验,对于偏好激进驾驶的用户,在安全范围内加快加速和变道响应速度;对于保守型用户,则增加安全距离,放缓驾驶操作,让用户感受到专属的驾驶服务。
3.4 非驾驶拓展场景
理想汽车对 VLA 架构的非驾驶场景拓展已进入实践阶段。在一次物流园区的测试中,自动驾驶货车利用 VLA 模型与仓库管理系统进行语言交互,准确理解 “前往 3 号仓库卸货” 的指令,自主规划路径,精准停靠装卸货区域,相比传统人工驾驶,装卸货效率提升 30%。此外,企业还探索将 VLA 技术应用于室内,测试车辆在室内环境中实现了物品搬运、环境感知与导航等功能,为未来智能生活场景提供了新的可能性。
4. 部分车企与供应商在 VLA 领域研发进展
4.1 小鹏汽车
小鹏通过 XNet + XPlanner + XBrain 三合一架构实现技术突破,端到端模型支持 50 城城市 NOA,AI 鹰眼视觉方案取消激光雷达,降低成本 70%。保持每 2 天一次的高频版本更新,数据反哺算法效率超特斯拉,但极端天气可靠性存疑。硬件成本大幅降低,覆盖 7 万 - 20 万元车型,日均新增训练里程 7200 万公里。AEB 支持 100km/h 刹停,代客泊车成功率 99%,但高阶功能(如城市领航)仍需 OTA 迭代。
目前在VLA应用开发方面,技术路线采用视觉+LiDAR双冗余,语言模块与阿里云通义千问合作。当前XNGP系统支持语音指令介入自动驾驶(如“绕过那辆自行车”),视觉-语言联合训练模型XNet。本土化适配过程中,主要是针对中文复杂指令优化(如方言处理),且注重人机共驾,语言指令可直接触发控制层动作。
4.2 理想汽车
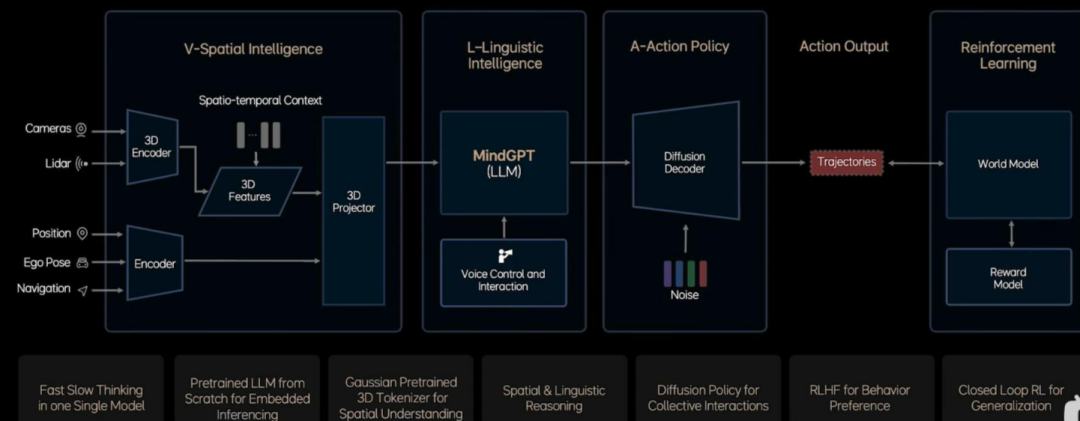
理想汽车于 2025 年 3 月 18 日在 NVIDIA GTC 2025 全球科技大会上正式发布下一代自动驾驶架构 MindVLA,将其定义为 “机器人大模型”,融合空间智能(3D 高斯建模)、语言智能(自然语言交互)和行为智能(Diffusion 轨迹优化)。通过自研 3D 高斯表征技术,实现多尺度几何建模与语义理解,支持无地图自主泊车、语音指令动态调整路线等复杂场景。采用并行解码和 ODE 采样器优化,车端推理速度提升至 2 - 3 步生成轨迹,并通过 RLHF 微调对齐人类驾驶偏好。针对中国复杂路况,借助 VLM 实现动态逻辑推理,突破传统方案依赖先验地图的局限。首款搭载 VLA 技术的纯电 SUV 理想 i8 计划于 2025 年 7 月正式发布,MindVLA 架构已完成工程化适配,预计 2026 年在量产车型中正式搭载,未来还将拓展至室内等非驾驶场景。
4.3 华为(*待斟酌,部分描述来自大模型,未必准确仅供参考)
华为 ADS 3.0 以端到端仿生大脑设计和多传感器深度融合为核心。整合激光雷达(探测距离 200 米)、毫米波雷达与 AI 视觉算法,构建 360 度环境模型,城市 NCA 接管率低至 0.5 次 / 百公里。CAS 3.0 全向防碰撞系统支持 23 项主动安全功能,实现车位到车位智驾全场景贯通,泊车代驾覆盖 100 个商业停车场。
官方表态:华为高层明确提出“不走VLA路线”,转而强调WA(World → Action)模型,即直接从感知世界映射到动作,不依赖语言中介。
但是在 ADS 系统中,华为引入了司机大模型(Driver LLM / VLM),具备对语义化指令的理解和转化能力。例如用户说“绕开前方事故车”,车辆能理解并执行,这显然体现了语言理解融入驾驶决策链路。在防御性驾驶(如识别潜在风险并采取绕行)、暴雨高速场景稳定性、驾驶平顺性优化方面,华为的端到端+VLM架构已经展现出VLA思想:通过语言或语义层信息增强驾驶决策鲁棒性。
华为更像是采取 WA 为主、VLA 为辅的策略。WA 路线保证主干推理的高实时性和安全性(少一层语言转换,减少延迟)。融合 VLA 元素(语言指令/语义层增强)来提升用户交互性和场景覆盖度。这也解释了为什么一些用户或媒体会觉得“华为其实走了 VLA 路线”,但官方又强调自己是不同于 VLA 的 WA 路线 ——两者并不矛盾。
4.4 供应商进展
英伟达作为芯片供应商,其即将量产的 Thor 系列芯片,单片 AI 算力最高达 1000Tops,在性能上对大模型有更好支持,为 VLA 模型在车辆端的运行提供了硬件基础,受到理想、吉利等车企青睐。元戎启行自研的VLA模型深度融合视觉感知、语义理解与动作决策三大能力,基于GPT-Transformer架构构建,具备强大的思维链推理和因果分析能力,有效克服了传统端到端模型的“黑盒”局限。元戎通过DeepRoute IO 2.0平台提供量产支持,该平台以“多模态+多芯片+多车型”为设计理念,兼容激光雷达与纯视觉两种感知方案,并可适配多种主流芯片平台,首批量产车型将于2025年第三季度落地。卓驭科技提出端到端世界模型架构,通过 Vision Encoder 和若干 Tokenizers 编码多模态数据,包括传感器数据、导航信息、历史轨迹、用户驾驶风格和语音文本输入,采用预训练和后训练方式实现硬件无关的平台化训练,适用于不同传感器构型和芯片类型,并计划在 2025 年内将个性化生成式智驾功能 GenDrive 量产搭载,该功能可实现自定义场景级驾驶风格、在线学习和模仿用户驾驶风格、自然语言交互控制驾驶风格和动作等。
5. VLA技术路线差异
5.1 传感器配置差异
理想 MindVLA、华为 ADS 3.0 等部分方案采用激光雷达、毫米波雷达与摄像头结合的多传感器融合方案,利用激光雷达高精度的距离探测优势、毫米波雷达对运动目标的检测能力以及摄像头丰富的视觉信息,构建全面精确的环境感知。如华为 ADS 3.0 的激光雷达探测距离达 200 米,能有效应对远距离目标检测。而特斯拉 FSD V12 坚持纯视觉方案,仅依靠 8 个摄像头输入,通过强大的算法和大规模数据训练模型来识别和理解环境,其优势在于降低硬件成本,但在复杂天气(如雨、雾、雪)及特殊光照条件下,视觉感知易受影响。比亚迪天神之眼则提供多版本选择,既有纯视觉的低成本方案(天神之眼 C),也有搭载激光雷达的中高端方案(天神之眼 A、B),满足不同市场定位与成本需求。

5.2 模型架构与数据处理差异
理想 MindVLA 创新性地融合空间智能、语言智能和行为智能,通过 3D 高斯建模、自然语言交互和 Diffusion 轨迹优化,实现从感知到决策的一体化。在数据处理上,强调对复杂场景的实时推理与泛化能力,通过并行解码和 ODE 采样器优化提升车端推理速度。
华为 ADS 3.0 基于端到端仿生大脑设计,多传感器数据深度融合后,利用 AI 视觉算法构建环境模型,数据处理注重全场景覆盖与安全冗余,如 CAS 3.0 全向防碰撞系统。小鹏的 XNet + XPlanner + XBrain 架构则通过多模块协作,提升模型可解释性与推理能力,数据更新频率高,以快速迭代适应不同场景。
5.3 应用场景与市场定位差异
理想 MindVLA 聚焦于将汽车打造为 “能思考的智能体”,除常规驾驶场景外,还着眼于拓展至室内等非驾驶场景,首款搭载车型理想 i8 面向中高端新能源汽车市场,强调智能化体验与多场景适用性。华为 ADS 3.0 凭借高安全性与全场景智驾能力,在 30 万以上高端车型市场建立优势,通过鸿蒙生态实现跨设备协同,拓展应用边界。小鹏 XNGP 以较低成本实现端到端大模型应用,覆盖 7 万 - 20 万元车型,主打中低端市场,通过高频 OTA 迭代提升功能实用性。
总 结
本文从视觉-语言-动作(Vision-Language-Action, VLA)的技术路线、应用场景、各家发展现状等方面入手阐述了整个VLA应用现状。其核心价值在于提升人车交互能力、增强环境适应性和优化决策智能化。VLA模型正在成为自动驾驶从“功能驱动”迈向“智能交互”的核心技术,其应用覆盖自然交互、环境理解、决策控制三大层面。目前,部分领先企业已实现部分功能落地,但实时性、安全性和泛化能力仍是待突破的瓶颈。未来,随着多模态大模型和强化学习的进步,VLA有望成为高阶自动驾驶(L4+)的标配架构,并重新定义人车关系——从“被动乘坐”到“主动对话与控制”。

版权声明
本文仅作者转发或者创作,不代表旺旺头条立场。
如有侵权请联系站长删除





发表评论:
◎欢迎参与讨论,请在这里发表您的看法、交流您的观点。